Christian Kleinerman
Microsoft Corporation
April 2005
Updated June 2005
Applies to:
Microsoft SQL Server 2005
Multiple Active Result Sets (MARS)
Summary:
All Microsoft SQL Server data access application programming interfaces
(APIs) provide an abstraction to represent sessions and requests within
those sessions. SQL Server 2000 and earlier restricted the programming
model such that at any point in time there would be at most one pending
request on a given session. SQL Server 2005 implements Multiple Active
Result Sets (MARS), which removes this constraint. This document
explains the design, architecture, and semantic changes in MARS and
what considerations must be taken into account by applications to get
the maximum benefit out of these improvements. (15 printed pages)
Contents
Introduction
SQL Server 2000 Data Access Recap
"Connection Busy"
"I Already Have MARS"
How Do I Do It Then?
Transactions and Execution Environment Recap
Multiple Active Result Sets - MARS
Interleaved Execution
MARS Performance and Cost Considerations
Transaction Semantics
Savepoints
Execution Environment
MARS Deadlocks
Monitoring and Diagnostics
Conclusion
Introduction
All
Microsoft SQL Server data access APIs provide an abstraction to
represent sessions and requests within those sessions. SQL Server 2000
and earlier restricted the programming model such that at any point in
time there would be at most one pending request on a given session.
Several alternatives have been implemented to work around this
limitation, of which the use of server-side cursors is probably the
most common. SQL Server 2005 implements Multiple Active ResultSets
(MARS), which removes this constraint. This document explains the
design, architecture, and semantic changes in MARS and what
considerations must be taken into account by applications to get
maximum benefit out of these improvements.
SQL Server 2000 Data Access Recap
The
main data access APIs currently supported to build applications against
SQL Server are ODBC, OLEDB, ADO, and the SqlClient .NET Provider1.
All of them provide an abstraction to represent a connection
established to the server and another one to represent a request
executed under that connection. For example SqlClient has SqlConnection and SqlCommand objects while ODBC uses handles, with SQL_HANDLE_DBC and SQL_HANDLE_STMT types, respectively.
An
execution request sent to SQL Server can be, for the most part, in one
of two forms: 1) a set of T-SQL statements commonly known as a batch,
or 2) the name of a stored procedure or function accompanied by
parameter values if appropriate. Note that submitting a single SELECT or DML statement to the server is simply a single statement batch, a special case of the first type of the request.
In
either case, SQL Server iterates over the statements contained in the
batch or stored procedure and sequentially executes them. Statements
may or may not produce results, and statements may or may not return
additional information to the caller.
Results are primarily produced by SELECT and FETCH statements. SQL Server executes a SELECT
statement by streaming the results back to the caller. This means that
as rows are produced by the query execution engine, they are written to
the network. More precisely, rows produced are copied into pre-reserved
network buffers, which are sent to the caller. Network write operations
will succeed and free up used buffers as long as the client driver is
reading from the network. If the client is not consuming results, at
some point network write operations will block, network buffers will
fill up in the server, and execution must be suspended, holding onto
state and execution thread until the client driver catches up reading.
This mode of producing and retrieving results is what is commonly
referred to as "default resultsets," also more informally referred to
as "firehose cursors."
Additional information may be returned to
the caller in other ways that may not be as obvious as the case for
results. Errors, warnings, and informational messages are types of one
such case, either returned explicitly by PRINT and RAISERROR statements or implicitly by warnings and errors produced during statement execution. Similarly, when a NOCOUNT set option is set to OFF,
SQL Server sends a "done row count" token for each statement executed.
This additional information can also potentially lead to network write
buffers filling up and a suspension of execution.
This
background enables us to understand some of the programming model
restrictions observed on SQL Server 2000 and earlier versions in terms
of supporting more than one pending request per connection.
"Connection Busy"
For
the examples in this document, we'll assume a simple scenario of a
loosely coupled inventory-processing system that uses a table called
"Operations" as a queue to receive requests from a variety of other
components:
Table 1. Operations
| Column Name | Data Type | Comments |
| processed | bit | |
| operation_id | int | primary key |
| operation_code | char(1) | 'D' - decrease inventory
'I' - increase inventory 'R' - reserve inventory |
| product_id | uniqueidentifier | |
| quantity | bigint | |
Let's assume that this component manages inventory for a variety of product lines and suppliers, and the product_id
determines which servers and databases to use and how to perform the
requested operation. (That is, let's assume that it is not possible to
write a few set-based operations that will take care of all requests in
the queue).
This component sits running in a loop, processing
requests inserted into the table, and marking them as processed upon
successful completion of the specified operation.
In pseudo code this would look something like this:
while (1)
{
Get all messages currently available in Operations table;
For each message retrieved
{
ProcessMessage();
Mark the message as processed;
}
}
An initial approach using odbc would look something like this (omitting some details and error handling):
SQLAllocHandle(SQL_HANDLE_STMT, hdbc1, &hstmt1);
SQLAllocHandle(SQL_HANDLE_STMT, hdbc1, &hstmt2);
while (true)
{
SQLExecDirect(hstmt1, (SQLTCHAR*)"select operation_id,
operation_code, product_id, quantity from dbo.operations
where processed=0", SQL_NTS);
while (SQL_ERROR!=SQLFetch(hstmt1))
{
ProcessOperation(hstmt1);
SQLPrepare(hstmt2,
(SQLTCHAR*)"update dbo.operations set processed=1
where operation_id=?", SQL_NTS);
SQLBindParameter(hstmt2, 1, SQL_PARAM_INPUT, SQL_C_SLONG,
SQL_INTEGER, 0, 0, &opid, 0, 0);
SQLExecute(hstmt2);
}
}
However, the attempt to execute hstmt2 resulted in this:
[Microsoft][ODBC SQL Server Driver]Connection is busy with results for another hstmt.
The same logic written in Microsoft Visual C# using SqlClient would look something like this:
SqlCommand cmd = conn.CreateCommand();
SqlCommand cmd2 = conn.CreateCommand();
cmd.CommandText= "select operation_id, operation_code, product_id, quantity
from dbo.operations where processed=0";
cmd2.CommandText="update dbo.operations set processed=1
where operation_id=@operation_id";
SqlParameter opid=cmd2.Parameters.Add("@operation_id", SqlDbType.Int);
reader=cmd.ExecuteReader();
while (reader.Read())
{
ProcessOperation();
opid.Value=reader.GetInt32(0); // operation_id
cmd2.ExecuteNonQuery();
}
Similarly, the attempt to execute this results in the following:
InvalidOperationException, There is already an open DataReader associated with this Connection which must be closed first.
These errors are the most direct demonstration of the lack of
MARS; at any time, at most one request can be pending under a given SQL
Server connection.
I intentionally left OLEDB out, given that it exposes a slightly different behavior.
"I Already Have MARS"
OLEDB
deserves special treatment in regards to MARS, since previous releases
of the SQLOLEDB client driver attempt to simulate MARS. However, this
attempt has many pitfalls. An OLEDB snippet of the above example would
look something like this (again, no error handling):
pIDBCreateCommand->CreateCommand(NULL, IID_ICommandText, (IUnknown**) &pICommandText);
pIDBCreateCommand->CreateCommand(NULL, IID_ICommandText, (IUnknown**) &pICommandText2);
pICommandText->SetCommandText(DBGUID_DBSQL,
OLESTR("select operation_id, operation_code, product_id, quantity
from dbo.operations where processed=0"));
pICommandText2->SetCommandText(DBGUID_DBSQL,OLESTR("update dbo.operations
set processed=1 where operation_id=?"));
//Execute the command
pICommandText->Execute(NULL, IID_IRowset, NULL, &cRowsAffected, (IUnknown**) &pIRowset);
...
ProcessOperation();
...
//Execute the command 2
pICommandText2->Execute(NULL, IID_IRowset, NULL, &cRowsAffected, NULL);
Interestingly enough, this code succeeds and seems to do what
I wanted. How does it succeed if the lack of MARS seems to be a
fundamental engine limitation? Upon some more inspection it becomes
apparent that the SQLOLEDB driver is spawning a new connection under
the covers and executing Command2 under it. This means I already have MARS, right? Not quite.
Nothing
special is done in the database engine to have these two connections
work well together. They're simply two connections, and as such they'll
have different execution environments, and probably more importantly,
they can conflict with each other. SQLOLEDB prevents a new connection
to be spawned whenever a session is in an explicit transaction, either
because of an explicit call to ITransactionLocal->StartTransaction
or because the session has been enlisted in a DTC transaction. In this
case, execution of command 2 fails.
However, if one of the
commands begins a transaction through TSQL, SQLOLEDB is unaware of this
state and allows the creation of an additional connection.
Unfortunately, two different commands, seemingly part of the same
session, end up running under different transactions.
Raising
the isolation level of the session—say to REPEATABLE READ—leaves the
application snippet above in a deplorable state. Command 1 runs the
query that retrieves all unprocessed rows in the operations table.
Given the higher isolation level, locks are held until the transaction
ends. Given that no explicit transaction is being used, the statement
is running in auto-commit mode and locks will be held until the end of
the statement. If a lock is being held on a particular row at the time
that command 2 attempt to modify it, a deadlock involving the client
code occurs and the application will simply hang.
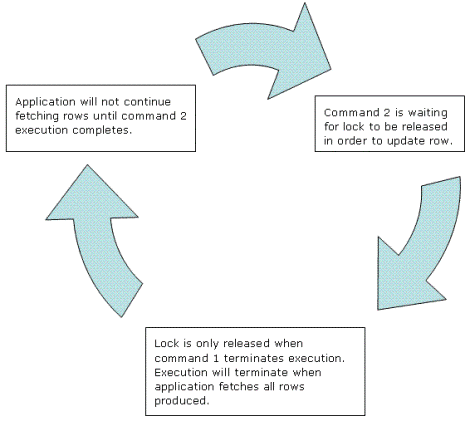
Figure 1. Multiple simultaneous command cycle
To
make things slightly less predictable, the statement in command 1 will
be complete at the time the last row produced is copied to the network
buffers in the server, not at the time that the client application
reads the last row. The implication behind this is that for a small
enough rowset, the code snippet above will succeed, but it will fail as
soon as the data volume is large enough such that the server can not
complete execution of command 1 by the time command 2 executes. It
wouldn't be surprising to see the application behaving as expected in a
development environment and mysteriously hanging when deployed in
production.
Bottom-line, it may not be the best application
design to rely on the emulated MARS-like behavior of SQLOLEDB. If you
decide to use it, be aware of the additional implicit connection and
the semantic implications this may have.
How Do I Do It Then?
Given
the lack of MARS in SQL Server 2000 and earlier, how do I get my
application to work? Depending on the application needs, sometimes
explicit use of multiple connections is needed. In many other cases,
use of server-side cursors comes in handy.
Server-side cursors
provide a way for applications to consume the results of a query with
one row or a small block of rows at a time. Without going into all the
details on different types and options, in the most general sense a
cursor represents the results of a query. It maintains the in-memory
and on-disk state such that results for the query can be returned on
demand.
In the general usage pattern, a cursor is declared on
top of a specified query. A fetch operation is executed to retrieve
each row or block of rows from the result set. Once the rows are
consumed or the result set is no longer needed, the cursor is disposed,
which frees up the associated server-side resources. The most important
thing to note in the context of this discussion is that there is no
code executing on behalf of the cursor in between fetch operations.
There is state preserved, but no pending work on the server.
ODBC and OLEDB expose properties such that query requests can be mapped to use server-side cursors.
Changing
the ODBC example above to have the first command use server-side
cursors makes the application scenario succeed and work as expected. A
one line change:
SQLSetStmtAttr(hstmt1, SQL_ATTR_CURSOR_TYPE, (SQLPOINTER)SQL_CURSOR_DYNAMIC, 0);
A similar change can be made to OLEDB to help avoid the implicit spawning of connections and associated pitfalls.
Up
to this point we've seen how server side cursors can help work around a
lack of MARS. As it will be described later, this does not imply that
the availability of MARS eliminates all needs for cursors, or that all
applications using cursors must be changed to use MARS.
The
natural follow up question is, "why not always use server-side cursors
instead of the seemingly more limited default result sets?" There are
three answers: 1) not all cursor types are supported on all valid SQL,
2) cursors can only operate on a single SELECT statement at a time, and 3) performance.
Default
result sets perform better than server-side cursors due to the way
results are "pushed out" as they become available. Cursors, on the
other hand, require a roundtrip to the server for each fetch operation.
In
conclusion, we can say that MARS is all about getting rid of
"Connection Busy," a significant improvement to the programming model.
Transactions and Execution Environment Recap
A session in SQL Server 2000 and earlier releases can be in any the following possible states:
- No transaction active: This is commonly known
as auto-commit mode, which implies that all statements executed in the
session run on a separate transaction.
- Local transaction active: All statements executed in the session run under a transaction that was started either by an explicit TSQL BEGIN TRANSACTION command, or by setting IMPLICIT_TRANSACTION ON.
- Enlisted:
A session is enlisted in a transaction owned by another session or by a
different transaction manager. The former is achieved by using bound
sessions (sp_getbindtoken / sp_bindsession), and the latter by enlisting in DTC transactions.
Given
that MARS was not available, it was never possible to have at any given
time more than one statement executing under the same transaction. Even
in the case of bound sessions or DTC, the underlying infrastructure
would ensure that work can only happen under the transaction context in
a single session at a time.
In ODBC and OLEDB/ADO, once a
transaction is started on a session, all subsequent requests are
executed under such a transaction, creating the appearance of a
session-wide transactional context.
In SqlClient the model seems less intuitive. An API is provided to begin a transaction off the connection (SqlConnection) object that returns an abstraction (SqlTransaction)
representing the newly created transaction. In a seemingly arbitrary
fashion, once a transaction is created no request can be executed
without explicitly associating it to the transaction context. SqlClient
API has provisioned for a programming model in which transactions are
not necessarily globally scoped to a connection, multiple transactions
may be created under a given session, and requests can freely be mapped
to any of the active transactions. Though SQL Server 2005 does not
support multiple active transactions per connection, the programming
model already accommodates such a future enhancement.
Under
MARS, it is possible for more than one request to be pending under a
given session requiring a proper semantic definition for conflicts
occurring between requests running under the same transaction.
Similarly,
it would appear as if in SQL Server 2000 any change to the execution
environment a request made would become a session-global change. What
exactly does execution environment mean? It encompasses SET option values (ARITHABORT, for example), current database context, execution state variables (@@error), cursors, and temporary tables.
Executing a USE
statement within a request to change the current database results in
all subsequent requests executing under the new context. Similarly,
changing the value for a SET option within a batch would imply that all subsequent executions would run under the newly set value.
MARS
removes the assumption that at most a single request can be pending
under a given session and, while preserving backwards compatibility, it
defines more granular semantics for changes in the execution
environment.
Multiple Active Result Sets - MARS
At
this point you may have a vague idea of what MARS is. In a nutshell, it
is the ability to have more than one pending request under a given SQL
Server connection. For most cases this will directly translate to the
ability to have more than one default result set (firehose cursor)
outstanding while other operations can execute within the same session.
It is probably as important to delimit what MARS is not:
- Parallel execution: Though MARS enables more
than one request to be submitted under the same connection, this does
not imply that they will be executed in parallel inside the server.
MARS will multiplex execution threads between outstanding requests in
the connection, interleaving at well defined points.
- Cursor
replacement: As described earlier, there are some scenarios where
cursors represented a suitable workaround for a lack of MARS; it may be
valid to migrate those scenarios to use MARS. However, this does not
imply that all current usages of cursors should be moved to MARS.
By
default, all of the code snippets included in the previous section
"just work" when using MARS-enabled client drivers against a SQL Server
2005 server. Also, the deadlock scenario described above where the
application would hang now succeeds under MARS-enabled connection.
MARS-enabled client drivers are the following:
- The SQLODBC driver included in the SQL Native Client.
- The SQLOLEDB driver included in the SQL Native Client.
- The SqlClient .NET Data Provider included in the Microsoft .NET Framework, Version 2.0.
By
default, these drivers will establish MARS-enabled connections. If for
some reason it is desired to establish connections that expose behavior
of down-level drivers, each API provides an option to request non-MARS
connections.
SqlClient provides the MultipleActiveResultSets connection string option. If set to false, MARS is not enabled for the session. If set to true or omitted, MARS is enabled.
Similarly, ODBC provides a SQL_COPT_SS_MARS_ENABLED connection option, while OLEDB provides a SSPROP_INIT_MARSCONNECTION option. Again, these options may only be needed to disable MARS, since it is enabled by default.
Note MARS
is only available with SQL Native Client versions of ODBC and OLEDB
providers. Older versions of the providers have not been enhanced to
support MARS. Needless to say, new drivers cannot support MARS when
connected to SQL Server 2000 or earlier servers.
Interleaved Execution
At
its deepest level, MARS is about enabling the interleaved execution of
multiple requests within a single connection. This is, it allows a
batch to run and, within the execution, allows other requests to
execute. Note however that MARS is defined in terms of interleaving,
not in terms of parallel execution.
The MARS infrastructure
allows multiple batches to execute in an interleaved fashion, though
execution can only be switched at well defined points. As a matter of
fact, most statements must run atomically within a batch. Only the
following statements are allowed to interleave execution before
completion:
- SELECT
- FETCH
- READTEXT
- RECEIVE
- BULK INSERT (or bcp interface)
- Asynchronous cursor population
What
does this mean, exactly? This means that any other statement outside of
this list that is executed as part of a stored procedure or batch must
run to completion before execution can be switched to other MARS
requests.
As an example, imagine a batch that submits a long running DML statement; say an UPDATE
statement that will affect several hundred thousand records. If, while
this statement is executing, a second batch is submitted, its execution
will get serialized until after the UPDATE statement completes.
On the other hand, if the SELECT statement is submitted first, the UPDATE statement will be allowed to run in the middle of the SELECT statement. However, no new rows will be produced for the SELECT statement until the DML operation completes.
Once
again, this illustrates that MARS interleaves requests and it does not
imply parallel processing. Interleaving is not affected whether the
statements in the request are contained in a batch, an EXEC statement, or a stored procedure.
Note A RECEIVE statement is interleavable once rows have started to be produced. In the case of a RECEIVE statement executed inside a WAITFOR clause, the statement is not interleavable while it is in waiting state.
Note Bulk operations are only interleavable if executed under SET XACT_ABORT ON
and if either no triggers are defined in the table target of the insert
operation, or the option to not fire triggers has been specified. RECEIVE is also only interleavable if XACT_ABORT is set to ON.
Note Stored
Procedures written in any of the .NET languages will not interleave
while managed code is executing. If the inproc data provider is used,
the executed batch is subject to normal rules for interleaving and
atomic execution of statements.
MARS Performance and Cost Considerations
As
described earlier, MARS is the default processing mode for SQL Server
data access APIs. Its execution model—unlike server side
cursors—supports large batches of statements, possibly with an
invocation of stored procedures and dynamic SQL operations. Given the
"firehose" mode in which results are produced, the performance of a
default result set (MARS) is superior to that of a server-side cursor.
There's
some fine print, though. A default result set will produce results "as
fast as possible." However, this is true as long as the client driver
or application is consuming the results produced. If the application is
not consuming results, server-side buffers will fill up and processing
will be suspended until the results are consumed. While execution is
suspended, many resources are tied up: data and schema locks are being
held, and a server worker thread is tied up, including stack and other
associated memory. Note that this condition is not specific to MARS; it
represents the same overhead incurred in SQL Server 2000 and earlier,
when a single request would produce default result sets that would not
be consumed fast enough. MARS does not imply improvements in the
overhead of firehose cursors.
This resource tie up does not
happen in the case of server-side cursors. Somewhat related, depending
on the cursor type requested, additional semantics may be available
that do not exist for default result sets, namely scrollability and
updateability of the results.
Given the description of how
requests are processed, it should be straightforward to infer the usage
guideline for retrieving results from SQL Server (assuming
scrollability and updateability are not required): If results will be
consumed eagerly by the application, default result sets under MARS
provide the best performance and overhead characteristics. If results
are to be consumed lazily by the application, it is recommended to use
server-side cursors, FAST_FORWARD cursors in particular.
In
most cases the use of the MARS default result-sets is appropriate. What
are examples of lazy consumption of results, then? Think of
applications that execute a batch or stored procedure that returns
results, and the consumption of rows is dependent upon the completion
of operations that are external to the database: user input, UI
actions, synchronization with other tasks, and so on. Having requests
pending for long periods affects the scalability of applications and
SQL Server in general.
Transaction Semantics
The
introduction of MARS changed many of the existing assumptions inside
the database engine regarding transaction semantics and concurrency of
operations within a single transaction.
Whereas OLEDB used to
disallow the implicit spawning of connections whenever a transaction
was active in the session, and ODBC used to fail additional requests
with the "connection busy" error, in the MARS-enabled world these
combinations now succeed. If the session has a transaction active, all
new requests run under the specified transaction; if the session has no
transaction active, each batch runs in auto commit mode, implying that
each statement executed runs under its own transaction.
The model in the SqlClient managed provider is more explicit. Specific SqlCommands need to be associated to a given SqlTransaction object to specify under which transaction to run a specific request.
Generally
speaking, transactions determine isolation between multiple users.
However, under MARS it is possible to have more than one request
running under the same transaction, which makes requests compatible
with each other and avoids deadlocks as the one described in the recap
section. However, what happens if there are conflicting operations
between two requests under the same transaction?
There are a few possible cases, explained below:
- One request is reading some results (SELECT, FETCH, READTEXT,
for example). Another request modifies the data being read (DML
operation, for example). In this case, though the change operation
succeeds, the read operation is isolated from the changes and all data
read is seen as of the time when the read operation started. Note that
this case is only possible if the read operation started before the
modifying batch. If the DML statement gets to run first, then the read
operation will be serialized behind and will see all of the changes
made.
- Two requests attempt to modify the same data. Given the
rules of atomicity of statements, DML statements must always run to
completion before being able to allow other statements to run. As such,
two batches attempting to modify data will never interleave. The
requests will be serialized and results will reflect the order of
execution. Note that if the client application is multithreaded, this
may yield non-deterministic behaviors.
- A request is reading data (SELECT, FETCH, READTEXT,
for example) and any of the underlying object's schema is modified (DDL
operation, for example). In this case, the DDL operation is failed,
given that there are conflicting pending requests under the same
transaction. Note that this behavior also applies to an attempt to
change the schema of a service broker queue while a RECEIVE statement is producing results.
- Overlapping operations happen on a table that is being bulk inserted into. BULK INSERT (or bcp, IRowsetFastLoad)
is allowed to run non-atomically, that is, to interleave with other
statements. However, no DDL, DML, or read operation can be concurrently
performed on an object target of a BULK INSERT. In such a case an error is produced given that there are conflicting pending requests under the same transaction.
Remember
that the cases described above only apply to requests running under the
same transaction. For requests running under separate transactions,
regular locking, blocking, or isolation semantics apply.
By the
way, the transaction semantics observed under MARS are implemented by a
transaction framework now also used by bound sessions and DTC. This
means that where it was previously possible to change the transaction
context between sessions only when no requests were pending, it is now
possible to switch context during the same set of statements that are
enabled to run non-atomically. Similarly, transaction context can not
be switched while DML, DDL, and other statements that must run
atomically are executing.
Note An attempt to commit a transaction will fail if there are pending requests under the given transaction.
Savepoints
Transaction
savepoints are commonly used to allow partial rollbacks within a
transaction. Typically, applications begin a transaction, set a
savepoint, do some work, and if the work succeeds then continue, and
roll back to the savepoint otherwise. The following example shows an
interaction of two requests with savepoints running under the same
transaction:
Table 2. Transaction savepoints
| Time | Batch 1 | Batch 2 |
| T1 | begin transaction; | |
| T2 | delete dbo.operations where operation_id=5; | |
| T3 | | save transaction sp1; |
| T4 | | insert dbo.operations default values; |
| T5 | delete dbo.operations where operation_id=10; | |
| T6 | | insert dbo.operations default values; |
| T7 | | if @@error>0
rollback transaction sp1; |
| ... | | |
| Tn | Commit Tran; | |
In
the example above, the first request begins a transaction and does some
work (deletes a row). Batch 2 then begins to run (under the same
transaction) and attempts to set a savepoint to ensure that a given set
of statements either succeed or fail atomically within the transaction.
However, within the two statements executed by batch 2, a
delete operation from batch 1 is interleaved. Assuming that an error
occurs in batch 2, the request will attempt to roll back to the
savepoint sp1. However, this would "silently" also rollback the delete
operation performed by Batch 1 at T5.
To avoid these
unpredictable and hard to debug situations, MARS disallows setting
savepoints, rolling back to savepoints, and committing transactions
when there is more than one active request running under a transaction.
If the two requests above were to be serialized the operation would
succeed, but with the specified concurrent requests interleaving as
specified above the attempt to set a savepoint in batch 2 will fail
with an error.
Execution Environment
As
described earlier, it seemed as if the execution environment were a
global one across a session. Under MARS, what happens if more than one
request simultaneously changes the environment? An example to
illustrate:
Table 3. Multiple simultaneous requests example
| Time | Batch 1 | Batch 2 | Batch 3 |
| T1 | use operations; | | |
| T2 | | use msdb; | |
| T3 | select operation_id from dbo.operations; | select name from sys.objects; | |
| ... | | | |
| Tn | | | select name from sys.objects; |
The
previous example shows three batches running under the same connection.
Batches 1 and 2 change the database context and then run a SELECT statement. Batch 3, at a much later time, runs a SELECT
statement without specifying database context. If the execution
environment were a truly global state of the connection, the outcome of
the above combination would be fairly confusing and unpredictable for
application development.
MARS has a request level execution
environment and session level default execution environment. When a
request begins execution, the session level environment is cloned to
become the request level environment. Upon completion of the whole
batch, the resulting environment is copied back onto the session level
default execution environment.
Under this semantics, a
serialized sequence of requests (the only allowable behavior in SQL
Server 2000) gives the illusion of a single session global execution
environment. However, under concurrent MARS requests, changes made by a
request do not affect other concurrently executing requests.
In the example above, the session environment is copied onto each of batch 1 and batch 2, and the SELECT
statements in each batch run under the desired database context. Upon
completion, each copies (and overwrites) the session context. Note that
in this case, the resulting database for the session will be dependent
on the completion timing of batches 1 and 2. Assuming that batch 3
initiates execution once batches 1 and 2 have completed, the results
returned will correspond to either 'operations' or 'msdb' databases
depending on the timing of the initial two requests.
Keep in mind the context copying semantics when programming to multiple batches under MARS. Copying of the context includes SET options and the rest of the execution environment.
Note If
a batch is cancelled, the execution environment is copied back onto the
session default as of the time when the cancel request is acknowledged.
MARS Deadlocks
MARS
enables several new scenarios, but as it is usually the case with
powerful features, it also creates new opportunities for you to shoot
yourself in the foot. Consider the following example.
Traditionally,
triggers have been allowed on DML statements. SQL Server 2005 extends
the model to allow triggers to be defined on DDL statements. Consider
now an application that decides to return results to the caller from
within a trigger (not that you would ever follow this horrible
practice, of course). A SELECT statement is included inside a
trigger body definition. The pseudo code from the application's
perspective would look something like this:
Request 1: update table operations; // this will return results from the trigger.
For each row returned from the trigger
{
Request 2: Read from some other table based on current row;
}
With the example above we have created a new type of
application deadlock. Request 2 will attempt to execute once per row
that is returned from request 1. However, request 1 is a DML statement
and as such it must run to completion before it allows any other
statement to execute. The same rule applies to DDL statements. In this
case request 2 will not run until request 1 completes. However,
completion of request 1 is dependent upon execution of each request 2.
MARS
solves this problem by adding blocking network operations to the
deadlock detection chain. For the scenario above, The SQL Server
deadlock monitor will detect the situation and will fail Request 2 with
an error indicating that the session is busy with another request.
As
a general rule, keep in mind which statements must run atomically, and
ensure that no operation will block them from making progress. More
important, ensure it is not blocked by an operation that is dependent
upon the completion of initial statement.
Returning results
from triggers is one of the easiest ways to run into this situation.
For this and several other reasons it is highly discouraged to return
results from triggers. This includes SELECT statements without assignment clauses, FETCH statements without assignment clauses, PRINT statements, or other statements running with NOCOUNT set to OFF.
Monitoring and Diagnostics
As
we've seen, MARS has changed some of the core assumptions inside the
SQL Server engine. It is important to keep in mind some of the new
assumptions when monitoring and diagnosing a SQL Server instance.
A
SQL Server Process ID (SPID) represents a session in SQL Server. Given
the MARS absence in previous releases, it was common to associate SPIDs
with requests. It was common to think of retrieving the SQL text for a
given SPID. It was common to look at execution statistics in
sysprocesses for a SPID. All these may no longer be sufficient given
the scenarios enabled by MARS.
Though sysprocesses continues to display information for a session, a few enhancements are in place to help monitor MARS.
The new Dynamic Management View (DMV) sys.dm_exec_sessions
presents a new view of session information, including the session
default execution environment. Under this view, what have traditionally
been known as SPIDs are reflected under the session_id column.
Also, sys.dm_exec_connections
is available to show all physical and logical connections established
to the server. Logical connections are the virtual pipes within a
session established for each request running under MARS. For logical
connections, the parent_connection_id column is populated. The common session_id column also shows the relationship of multiple logical connections within a single session.
A new DMV, sys.dm_exec_requests, presents a detailed list of the requests available under each session.
A new intrinsic function, current_request_id(),
is also introduced to enable the programmatic finding of the currently
executing request's ID. This is analogous to the existing @@spid function.
Conclusion
Support
for Multiple Active Result Sets (MARS) in Microsoft SQL Server 2005
increases the options available to develop SQL Server applications. It
brings the cursoring programming model closer together with the
performance and power of the default processing mode of the relational
engine.
MARS provides a lighter weight alternative to some
applications that may have been using multiple connections to overcome
lack-of-MARS limitations. However, this is not always the case, since
multiple connections do provide parallel execution in the server
(provided they're not enlisted in the same transaction).
Though
in many situations MARS may provide an alternative to server-side
cursors and provide performance improvements, it is not a replacement
for cursors. As described in this white paper, there are cases where
MARS represents an attractive alternative, but there are many others
where cursors may scale better.
In a nutshell, MARS is a
programming model enhancement that allows multiple requests to
interleave in the server. Though it does not imply parallel execution
in the server, it may yield some performance benefits if used correctly.
1This document does not cover DB-Lib or the .NET Managed Providers that layer on top of ODBC/OLEDB.